|
|
|
|


|
|
|
|
L'ADN est avant tout une information. L'ADN contient, inscrit dans sa structure même, toutes les informations nécessaires à la cellule pour synthétiser les milliers de protéines différentes qui sont nécessaire à sa survie. C'est, en quelque sorte, l'équivalent du disque dur de votre ordinateur. Un disque dur sur lequel on retrouverait des recettes de protéines. Mais comment une molécule peut-elle constituer une information? Comment cette molécule peut-elle indiquer à la cellule comment synthétiser du lysozyme ou de l'hémoglobine? Prenons, comme exemple, l'information nécessaire pour synthétiser du lysozyme. On pourrait écrire cette information en représentant chacun des 130 acides aminés de la chaîne par trois lettres de l'alphabet latin. On obtiendrait ceci:
Les trois caractères LYS, par exemple, codent pour l'acide aminé lysine; les caractères VAL codent pour la valine, etc. Cependant, ce code serait inutilisable pour la cellule. On voit difficilement comment on pourrait entrer cette recette faite d'un alphabet latin dans la cellule et comment on pourrait lui apprendre à l'utiliser (à décoder la recette) pour fabriquer du lysozyme. Pourtant cette recette du lysozyme est bien présente dans chacune de vos cellules. Comme nous le verrons, elle n'est pas écrite avec des lettres de l'alphabet, mais avec des molécules, plus précisément des nucléotides. Les nucléotides forment un code que la cellule peut lire et reproduire. |
|
|
Pour comprendre ce code, utilisons une analogie. Supposons que vous voulez écrire un message secret en utilisant des billes de couleur que vous enfilez sur un fil. Vous devez donc faire correspondre des billes à des lettres de l'alphabet. Supposons aussi que vous disposez de seulement quatre couleurs de billes: rouge, jaune, vert et bleu.
C'est déjà mieux, on a maintenant 16 combinaisons possibles ( 42 ). Malheureusement, ce n'est pas assez puisque l'alphabet comporte 26 lettres.
« BABA » s’écrirait en enfilant dans l’ordre, les billes:
|
|
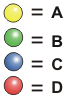 On
pourrait, par exemple, former un code où chaque bille correspondrait
à une lettre de l'alphabet. La jaune, par exemple, pourrait
correspondre à la lettre A, la verte à la lettre
B, la bleue à la lettre C et la rouge à la lettre
D. Vous voyez immédiatement le problème. Notre code
ne permettrait que de désigner 4 lettres sur les 26 de
l'alphabet. On pourrait écrire BABA (vert-jaune-vert-jaune)
ou BAC (vert-jaune-bleu), mais pas BIOLOGIE.
On
pourrait, par exemple, former un code où chaque bille correspondrait
à une lettre de l'alphabet. La jaune, par exemple, pourrait
correspondre à la lettre A, la verte à la lettre
B, la bleue à la lettre C et la rouge à la lettre
D. Vous voyez immédiatement le problème. Notre code
ne permettrait que de désigner 4 lettres sur les 26 de
l'alphabet. On pourrait écrire BABA (vert-jaune-vert-jaune)
ou BAC (vert-jaune-bleu), mais pas BIOLOGIE.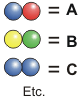 Regroupons
les billes deux par deux. Par exemple: bleu-rouge
correspondrait à "A", jaune-vert à "B",
bleu-bleu à "C" et ainsi de suite.
Regroupons
les billes deux par deux. Par exemple: bleu-rouge
correspondrait à "A", jaune-vert à "B",
bleu-bleu à "C" et ainsi de suite. 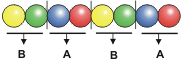
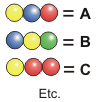 Regroupons
alors les billes par trois. Par exemple, décidons
que les trois billes jaune-bleu-rouge représentent
la lettre A, bleu-jaune-vert
la lettre B, jaune-rouge-rouge la
lettre C et ainsi de suite jusqu'à Z.
Avec des combinaisons de trois billes, on peut former 64
combinaisons différentes ( 43 ),
c’est plus que ce qui est nécessaire pour coder 26
lettres. On pourrait ainsi rédiger un message en enfilant
des billes de couleur sur un fil.
Regroupons
alors les billes par trois. Par exemple, décidons
que les trois billes jaune-bleu-rouge représentent
la lettre A, bleu-jaune-vert
la lettre B, jaune-rouge-rouge la
lettre C et ainsi de suite jusqu'à Z.
Avec des combinaisons de trois billes, on peut former 64
combinaisons différentes ( 43 ),
c’est plus que ce qui est nécessaire pour coder 26
lettres. On pourrait ainsi rédiger un message en enfilant
des billes de couleur sur un fil. 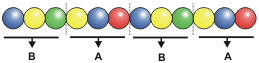
Quiconque connaît le code utilisé pourrait lire le message en regardant la succession des billes de couleur formant le chapelet. La séquence des billes constitue un message codé. Sauriez-vous, avec ce code, écrire « BAC »? Plutôt qu’utiliser des billes, utilisons quelque chose de beaucoup, beaucoup plus petit, des nucléotides. Il y a quatre sortes de nucléotides, A, T, C et G. Lions ces nucléotides les uns aux autres comme les billes de couleur de l'exemple précédent. On pourrait imaginer un code où chaque groupe de trois nucléotides correspondrait non pas à une lettre de l’alphabet (la cellule n’a que faire de l’alphabet romain) mais à un des 20 acides aminés formant les protéines. On pourrait ainsi former des messages correspondant à la recette d’une protéine.
On aurait ainsi une molécule (un polymère de nucléotides) qui représenterait, sous forme codée, la recette d’une protéine. On pourrait aussi mettre « bout à bout », des milliers de recettes différentes. Eh bien, l'ADN d'un chromosome, c’est exactement ça! Imaginez chaque chromosome comme une longue, une très longue succession de nucléotides, un chapelet pouvant avoir une centaine de millions de perles. Chaque groupe successif de trois nucléotides désigne un acide aminé selon un code préétabli connu par les cellules et chaque recette de protéine constitue un gène. C'est au début des années 60 qu'on a réussi à trouver le code (nous verrons plus loin comment) : |
|
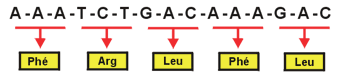
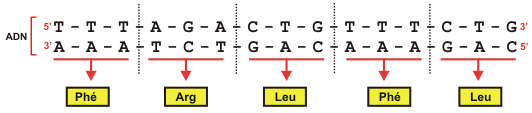
Voyez, par exemple, la séquence de nucléotides codant pour les acides aminés de la calmoduline, une enzyme intervenant dans la régulation de l'activité de plusieurs enzymes. Bien sûr, l'ADN est constitué de deux chaînes complémentaires. L'information n'est portée que par une des deux chaînes, parfois l'une, parfois l'autre. La chaîne complémentaire au message est là pour stabiliser la molécule et lui permettre de se reproduire (réplication). Le segment d'ADN correspondant à la recette d'une protéine est appelé gène. Le segment d'ADN ci-dessous correspond donc au gène de la protéine PHE-ARG-LEU-PHE-LEU
Gène de la protéine PHE-ARG-LEU-PHE-LEU. L'information est portée par le brin du bas (et elle se lit dans la direction 3' - 5' ). Le brin du haut sert à stabiliser la molécule et lui permet de se reproduire. L'ADN constitue donc une information miniaturisée (le minuscule noyau d'une cellule peut contenir des dizaines de milliers de gènes différents). Et le plus beau de l'histoire, c'est que cette information peut en plus se reproduire ! |
|
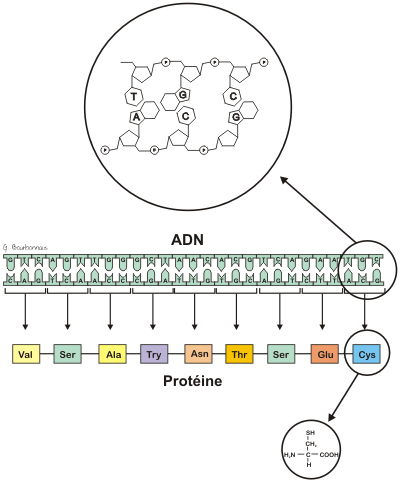
Le triplet de nucléotide ACG désigne la cystéine, ce n'en est pas! Voir : La structure de l'ADN et le code génétique (cliquez sur "Codon", le dernier bouton à droite).
Évitez une erreur fréquente, souvent vue dans les journaux : ne confondez pas code génétique et information génétique. Le code génétique, c'est la correspondance entre un triplet de nucléotides et un acide aminé. Ce code est le même pour tous les êtres vivants. L'information génétique, c'est la séquence des nucléotides, les recettes de protéines. L'information génétique n'est pas la même d'un être vivant à l'autre (sauf les clônes comme les jumeaux identiques). |
Combien
de nucléotides |
|
|